Written by
Heikki Orsila.
Version 0: 2009-11-02
Version 1: 2009-11-09
Thoughts on distributed version control and git
Contents
- Introduction
- Normal day at work
- Developer branches, repositories and merging
- Managing commits (the politics)
- Branching and merging is inherent to all development
- Transition from SVN to git
- git features
- Conclusions
- Links
- Author
I will try to document some of my thoughts on distributed
version control and how we use git
at
TUT's Department of Computer Systems.
git is a
distributed version control system
designed and implemented by Linus Torvalds and many others.
I became interested in distributed version control after I saw
Linus Torvalds' tech talk at Google. Torvalds' attitute was
rather politically incorrect, which may have caused some people to
dismiss his ideas about version control systems.
Having tried distributed version control for two years, I now feel
that Torvalds was right.
I start my day at work by looking at what other people have done.
I do this by looking at a metro track chart displayed by the gitk,
a tool that comes with git. I simply issue two commands:
$ git remote update
$ gitk --all
gitk usually gives me a picture something like this:
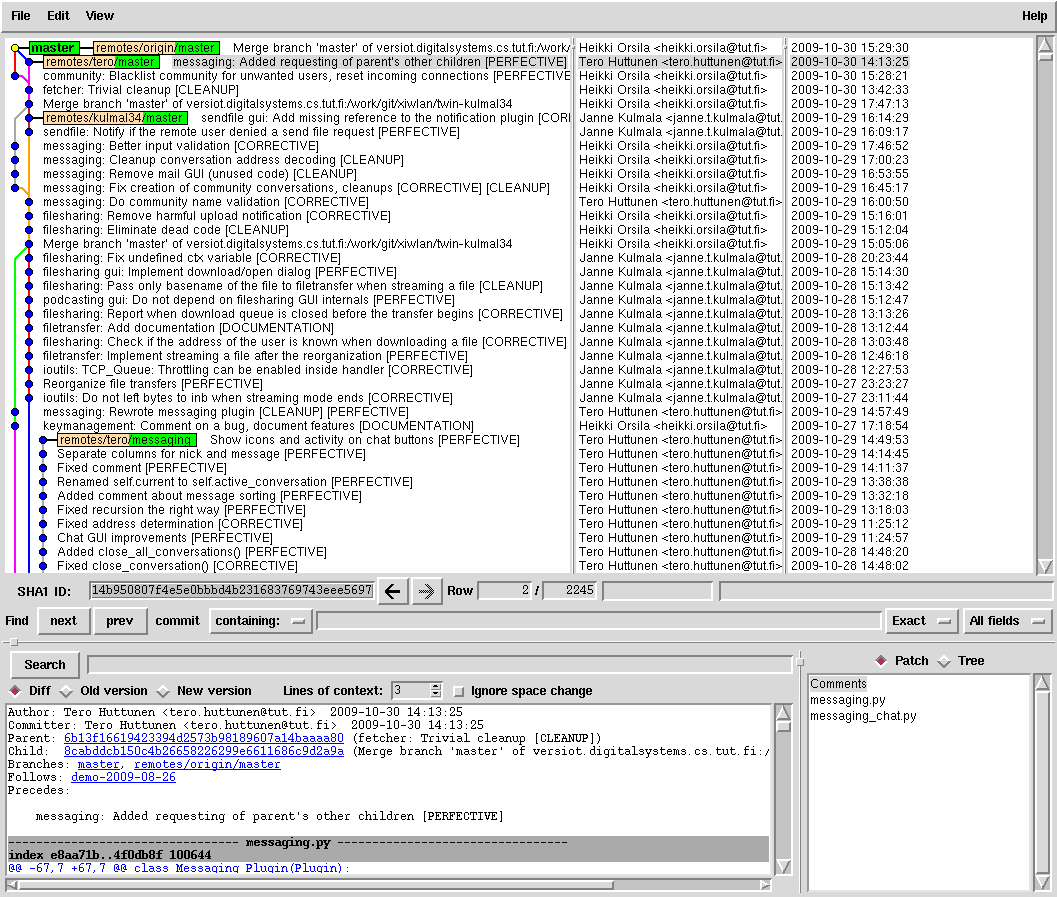
Each row in the chart represents a commit. Commit identifies a particular
state in the project. Time advances upward, the past is downward.
Merge is a commit where two states of a project are
fused together, that is, two or more metro tracks are joined together.
Branching point is a commit after which the project splits into two or more
separate commit lines. In above figure, the first row is a merge commit,
and the fourth row is a branching point.
A commit in git contains important meta data:
comment on the change,
author of the change,
committer of the change (not necessarily the same person!).
All branches and commits together form a directed acyclic graph that displays
parallel development on each of the projects repositories.
Repository (or repo) is a git tree that contains
one or more branches.
gitk allows me to see easily who is doing what in the project.
It shows the distribution and parallelism for tasks and people working
in the project.
Traditional centralized version control tools do not show the parallelism
aspect easily.
Each developer has a separate repository that contains the full
version history of the project. Each repository may contain several
branches. In our project there are approximately 10 branches,
but we mostly look at only a few of them.
Each developer has a master branch that is
the latest good version of the project.
In addition, we have several topic branches (git terminology)
that contain on-going work on specific features that are not yet ready to
be merged into developers master branches.
In the picture there are 3 master branches (tero/master, kulmal34/master
and shd/master (me))
and one topic branch (tero/messaging).
Changes between repositories are merged to drive the project
forward. As an example, if I decided that Tero's messaging topic branch
was mature enough for my master branch, I would merge it to mine. Or more
likely, I would ask Tero to merge it into his master branch, after which
I would merge his master with mine. Merging is easy and fast with git:
$ git pull tero messaging
It is as simple as that. Almost all the merges we do are conflict free,
but sometimes we have to fix some merging conflicts by hand:
$ git pull tero messaging
...
Auto-merging FILENAME
CONFLICT (content): Merge conflict in FILENAME
Automatic merge failed; fix conflicts and then commit the result.
$ edit FILENAME (fix merge conflict by hand)
$ git add FILENAME
$ git commit (edit changelog entry)
Creating a new branch is trivial:
$ git checkout -b new-branch
$ start editing && commiting
Switching between branches is easy:
$ git checkout master
$ git checkout any-other-branch
As each repository contains the full version history, changing a branch,
merging a branch, creating a branch is very fast.
git makes these operations in less than a second for a medium sized project.
Merging branches is so easy and fast in git that it becomes a natural
workmodel for developing new features.
We have a policy of not pushing commits to each others repositories or
branches. One may only push to ones own repo, but pull
from any repo.
This avoids accidental conflicts, because one can always know
that nobody has fudged with one's repository :-)
It happened to me once that a fellow developer had
commited 300 MiBs of crap into my SVN repository. We had to halt
development and cleanup the repository manually with SVN administration
tools.
Distributed version control is about gatekeepers and pull model.
Projects that need stability for a release need a gatekeeper.
Gatekeeper is the person who selects which features go into a release
so that it satisfies the requirements of customers/users.
Gatekeeper needs not be afraid of other developers in the pull model
because only the
gatekeeper may push changes to the stable/release branch.
This saves tons of problems.
git makes the gatekeeper easy and natural due its distributed
design.
All repositories are equal from git perspective, and therefore,
any possible workflow between repositories is equally supported.
Centralized development is also supported, although frowned upon.
git also provides a cherry-pick tool that helps picking independent
patches from other branches without actually merging the whole
branch.
The gatekeeper has several options
how to merge fixes/chandes into a stable branch:
- "git cherry-pick COMMITID" gets a single commit (change) from some repository
- "git pull person topic-branch" merges a single feature from a topic branch
- "git format-patch && git am PATCHFILES*" merges a series
of patches that come in git's external patch format that is a human
readable form to distribute patches on mailing lists and email.
In our project, my master branch is the gatekeeper for releases.
Everything that I merge will go the release. I will refuse to pull
changes that I feel can hurt the release.
In some cases, we have a separate demo branch that we will later
present to our customer. Only bug fixes and selected features
will go the demo branch.
As a gatekeeper, I would like to know what the intent of each commit is.
We have a policy, that each commit has one or more tags that put a commit
into one or more categories. If you look back at the picture,
you will see that each of our commits has a tag in the change message.
For example, commit on 2009-10-29 15:12:04 had a change message:
"filesharing: Eliminate dead code [CLEANUP]". The "[CLEANUP]" part has
a formal meaning that we have defined in our project's politics.
Here are the tags that we normally use:
- [CORRECTIVE] tag means the commit has a corrective effect on the project
- [SECURITY] is a special case of corrective effects that solves a problem
with external security, such as malicious input from the network that
allows attacker to take advantage or cause harm for the user.
- [PERFECTIVE] means the commit improves or adds a feature
- [CLEANUP] means the commit makes code more understanble
- [PREVENTIVE] means the commit is intended to reveal internal problems
in the code, e.g. add an assertion on function's parameter value to make
it non-negative (assert(x >= 0)).
- [ADAPTIVE] alter the project to be usable in some new environment.
For example, make the project support a new incompatible version
of a library.
- [DOCUMENTATION] is a commit that documents some feature or behavior
of the code.
- [WORKAROUND] is used when shit happens. In other words,
we can not find a good solution to a problem, or the solution can not
exist at all due to some external/compatibility/ambiquity factors.
Patch the thing to avoid worst case effects.
[CORRECTIVE] and [SECURITY] tags would be useful for Linux distribution
maintainers that may want to backport security and bug fixes from new
versions to distribution's older maintained packages.
"git log --grep=CORRECTIVE" will show all commits that have a
corrective effect on the project. Assuming of course that developers have
tagged their commits properly ;-) Mistakes do happen, but tagging makes
correction discovery statistically less effortful.
Commit annotation also gives some interesting statistics. Here is
the statistics for our project this year (not counting merge commits).
In 1248 commits, there are
- 517 (41%) commits improved or added a feature
- 368 (29%) corrective commits
- 163 (13%) cleanups
- 68 (5,4%) commits tried to prevent internal inconsistency (e.g. assetions)
- 14 (1,1%) security related commits
- 13 (1,0%) commits improved portability/adaptability to other environments
- 13 (1,0%) did documentation
- 6 (0,5%) commits workarounded some problem
Note, some commits belong to more than one category, so that above
statistics could add up to more than 100%. Also, not all of our commits
are annotated with a tag. There are commits like
"Update to do list" that have no tags.
You can checkout some of my Open Source projects as well to see how I
have applied these tags:
Consider a 3 developer project where each developer has a repository.
All developers may pull from all the other repositories,
but only push (write/commit) to their own.
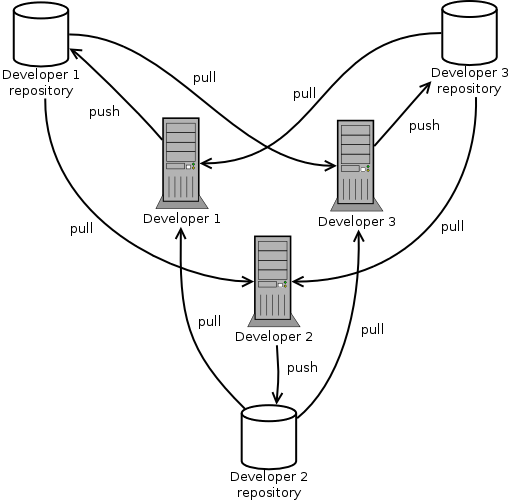
The picture may seem complicated, and one may wonder if the distributed
model makes sense at all.
However, changing the workflow into a single centralized repository
would not decrease the chance of conflict.
Parallel line of development always
brings the chance of conflict.
Working with same files or features is a problem, even if the model
is centralized.
Developers have to be careful to see each other's assumptions.
There is no silver bullet to this problem.
It is often the case that normal developers only track one repo,
usually the repository of the gatekeeper.
The above picture would be simplified.
It would almost lead to a centralized model, except that the
gatekeeper still pulls from each developers' repository:
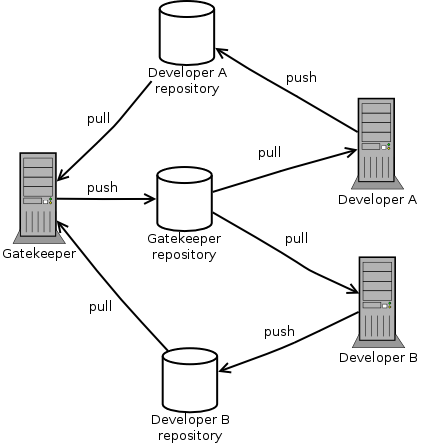
I would argue that a centralized model
in practice leads to more risks compared to the distributed model, because
the distributed model makes the developer think in terms of
parallelism. Both models have to solve the same problems, but
distributed model makes the parallelism more apparent than the
centralized solution.
I will admit that the change from centralized to distributed is not an
easy one for those who come from centralized (traditional) model.
I have taught some developers coming from SVN to work with Git, and the change
is not easy, but is not hard either. If one starts with the assumption
that git is the same as SVN, the transition is hard. One has to learn
some new concepts with git, and throw away old concepts. In my view
the new concepts in git are roughly:
- git commit does not imply the change is visible to others.
A push is needed after the commit so that the change becomes visible
to others. This also has a benefit: a git user may un-do a bad
commit before it comes visible to other developers. This actually
happens quite often.
- git tools are simple, but their syntax is different to SVN
- Branches in git are different views to the same repository, but in
SVN they are places inside the projects namespace. SVN users do not
"switch between branches", they just edit the project from a different
place. git users switch between "views" or branches so that only one
branch is visible at a time. However, a git user may have several
workspaces for the project that track different branches.
- git has an additional commit stage between a modified local file and
the repository. It is called the index.
Index is a place in which commits
are prepared. git commit will transfers all changes from
the index to the repository, but git has to be told what is put into the
index. This allows a delicate control on what commit will do.
The existence of index becomes almost invisible once the developer has
learned git's syntax.
Learning git features takes a long time, but it is not because git is
hard, but because git provides so many features that were not available
in SVN. Here are some of the features that I have found useful.
git bisect allows one to find out a commit that broke or changed
some feature by doing binary search in the commit tree. If one knows a
version in the past in which feature X worked, but
some newer version broke it, git bisect will assist you to find the
problematic commit by doing a binary search in the version history.
Each iteration approximately halves the number of suspected commits in
the tree. This means that is easy to find out the breaking commit even
if there are thousands of suspected commits (no more than, say 13 steps).
This has occasionally saved us a lot of debugging at work.
If the feature-X can be tested directly with a script,
git bisect run scriptname will automatically find the breaking
commit.
git rebase allows one to do two very useful things:
- Reorder, fix and patch together commits that are not yet published
to outsiders. That is, the commits have not yet been pushed visible to
other developers. git rebase -i HEAD~3 allows one to change
the order, fix and patch together last three commits. Patching commits
together is useful when one finds out that some of the commits actually
should go together. That is, one commit is broken without the other.
- Move topic branching point in retrospect. Often there are changes,
fixes and feature improvements in the main branch while one develops
a new feature in a topic branch. The changes from the main branch
can be imported to the topic branch by moving the branching (forking)
point of the topic branch. git does this by looking at the old
branching point, creates a set of patches from that point to the latest
commit in topic branch, and those patches are then applied on top of the
current main branch head. This allows one to get changes (benefits) of
the main branch while developing a new feature in a topic branch.
The rebase procedure is trivial unless there are conflicts:
git rebase master. Just one command is needed :-)
git reset is a tool that allows one to revert to an older state
of the project, completely destroying some commits. This is a bad
thing if one has already published the changes, but in local development
it is often useful.
git tag creates a tag for a single state of the project.
In git one can not commit under tags, unlike in SVN. It is unfortunate
to see people committing under SVN tags as the idea of the tag is that
the project is immutable in that part of the SVN namespace.
An additional feature of git tags is that one can sign the tags
with PGP key. Just do: git tag -u MY-PGP-ID release-x.y.z
git grep regular-expression allows one to grep for lines
inside the source code. git grep excludes files that are not versioned
in the repo.
Projects often store temp files and binary objects in the working
directory that one does not want to grep, git grep avoids this.
Also, I hated SVN for having ".svn/" directories
everywhere inside the working copy, because my grep and find statements
would show me irrelevant info or cause me unnecessary effort to
filter out files from ".svn/" directories.
git solved this problem with a simple tool.
git grep supports many grep(1) options.
git log --grep=x greps inside the changelog.
git uses a real name and an email address to identify persons who
authored some change and persons who commited (pushed) the change.
These are separate persons, so outside contributions can be attributed
to real persons. In the CVS and SVN days people used to write down
the names of authors into the change log as text, without any formal
notation. This often leads to a situation where it is not clear who
authored a given piece of code. CVS and SVN repositories
only have a pseudonym for each commit. Unfortunately pseudonyms are
restricted to the privileged core developers that have
commit access to the repository.
This may not be so important in the corporate world as it is in the
Open Source world.
Everyone has commit access in the distributed model,
git tracks authorship for each change exactly!
Each object (commit, file contents, file tree, ...)
in git is identified by an SHA1 checksum (160 bits) that
identifies the content. A single SHA1 presents the projects state and
its history up to that point so that it is cryptographically secure.
This is a content checksum model.
The SHA1 is derived from the content, not the physical place where it
resides. This makes all git repositories globally comparable.
Same code and same history has the exactly same checksum everywhere.
Note, this data model implies that git can not have a global
sequential revision numbering. One can not have version id 1, 2, and so forth.
They must be derived from the content.
git's data model has four surprising benefits:
- The content checksum model allows disk, memory and network errors to be
detected because each time git fetches/clones and object, it calculates
the SHA1. Errors in hardware are detected. No bitrot in copies:-)
Git never changes the data that you put into a repository.
It always comes out as you intended it to be.
- A single trusted commit ID (SHA1) is enough to trust an
untrusted data source.
git reset --hard COMMIT-ID will put the repository
into a trustable state, including its complete history, regardless of the
data source.
The other party can not have faked that commit id as git
verifies the content and history SHA1s up to that point from the single
commit ID number.
- Two files with the same content is stored only once in repository.
Every and all files in any project that have the same content are also
identified with the same SHA1 id. It doesn't matter how many copies of
the same content you have in files, it is stored exactly once in the
repository. Tracking even hundreds of branches
is space efficient because the same data is only stored once in the
repository. All the content is simply indexed with SHA1 checksums,
as with BitTorrent protocol where individual data blocks are content
hashed with SHA1.
- A merge needs to be handled only once in a multi-developer project.
Git uses the SHA1 commit ID and the acyclic commit/version
graph to deduce how a
merge is done. If developer 1 merges a branch from developer 2, and later
developer 3 merges from developer 1, the third developer need not do the
merge as the version graph indicates that developer 1 had resolved the merge.
No duplicate merging effort needed. It is fast and simple. Let's look at
three common cases. Assume A merges from B.
- If B is an ancestor of A, nothing needs to
be merged as A is already a follower from B's state.
- If A is an ancestor of B in the
version graph, it is known that B has already handled the merging path
from commit A to B.
Git does a trivial merge which is called fast-forward.
No conflicts can happen in this situation as there is no parallel
development.
-
If A is not an ancestor of B, but they have a common ancestor C (they almost
always have one), git uses a recursive merge strategy
that analyzes the two paths from C to A, and C to B. Actually, git only
needs to look at exactly three points: A, B and C. Git looks at differences
in files between A, B and C and does a 3-way merge on the individual files.
Some of the files may have conflicts, and git informs the developer to
fix those files.
There is a fourth case in which the two branches have no common
ancestry at all. This is very rare. This usually happens when the
other branch has rewritten history after publishing it, or when the
other branch started from some snapshot of the project without history.
In this case, the only real alternative is to try
3-way merges on all files of each branch. However, after this merge is
done, the two previously unrelated trees are then related to each other.
git approach also has a downside. Rewriting history (rare, but sometimes
needed) is slower and changes version numbering from the change to all
subsequent children. "git filter-branch" is a fast tool to rewrite history, but
it may take tens of seconds (or even minutes) to rewrite thousands of
commits in a large project. One can not ever remove anything completely
from a git project without rewriting history. Fortunately this is rare,
and the tool (git filter-branch) is provided if you need to do it.
Because each developer stores the full version history on the local
workstation, operations that look into version history are very fast.
Network round trip times will blow the performance for large operations
that need to lookup thousands of elements from the repository.
The speed difference can be felt even on simple operations like
diffing two versions of the tree. git will compare two revisions in a
snap.
There are exceptions however.
Some operations, like git blame,
may be slower in git compared to SVN.
git blame is slower than svn blame because git does not store
changes per file, but SVN does. git will have to do a search backwards in
time in the metro track chart (the version control graph) to find out
commits that changed each line. Usually this takes less than a second
in git, but it can easily take several seconds in projects that have
many years of history. In extreme cases, like the Linux kernel, it
can take a minute (on my Pentium 4) to scan through the MAINTAINERS file
(1575 commits in 4.5 years).
Interestingly, git log MAINTAINERS shows all changes with authors
and comments in just three seconds, so very fast to grep through changelog.
Getting all the patches for the MAINTAINERS file
(git log -p MAINTAINERS) is only 7.5s.
All in all, git may have a spoiling effect on people who like
fancy a responsive tool ;-)
Going back to SVN (and waiting for too many network round trips per
operation) seems like a bad idea.
Git compresses the version history to a very small size. Objects are
packed internally by delta diffing and zlib compression.
Often the repository size is much lower than with SVN. Even the initial
clone which requires the full version history can be much faster than
only checkout a trunk of the SVN repository. At work we tried converting
a 200MiB SVN repo to Git. The initial git clone was only a third in time
when compared to svn trunk checkout. Further, SVN working copy had
three times the number of files inside countless ".svn/" directories
in the tree, as compared to git which just stored all the
repository objects under just one directory, the
".git" directory at the root of the project. The resulting git working
copy with full repository was smaller in size than the SVN trunk checkout.
Syncing updates is very fast after an initial clone of the project.
It has happened more than once that our version control server at
work is inaccessible for some period of time. Distributed version
control means that each developer has access to the version history
even if network is broken, the version control server breaks down,
or one is working on a trip without a network connection.
All developers do automatic backups of each other, because each developer
tracks the full history of the project, possibly including other
developers topic branches. If just one workstation/laptop
survives a catastrophy, all data and history is recovered, except perhaps a
few changes since the last sync.
Distributed version control is inherently more reliable than
centralized servers with respect to data consistency when and if
some kind of content checksum is used. Fortunately, all
modern distributed version
control systems use checksums to detect corruption.
Investigation and experience in distributed version control with git
has led me to change how I work with software projects.
My workflows are now more predicable. However, unpredictable
workflows are easier too.
I can manage and grasp changes from several people
easier than I did in the past.
git has provided me with a tool that is feature rich and hugely more
usable than CVS and SVN were.
Please send any feedback and suggestions to
Heikki Orsila.